Fraktální komprese
Obsah
Historie
Fraktální kódování je matematický postup používaný ke kódování bitmapových obrazů reálného světa jako množiny matematických dat, která vyjadřují fraktální vlastnosti obrazu. Fraktální kódování vychází ze skutečnosti, že všechny přirozené a většina umělých obrazů obsahují nadbytečné informace ve formě podobných, opakujících se vzorů, tzv. fraktálů.
Fraktál je struktura tvořená podobnými vzory a obrazy, které se vyskytují v mnoha různých velikostech. Pojem fraktál poprvé použil matematik IBM Benoit Mandelbrot při popisu opakujících se vzorů, tento jev pozoroval v mnoha různých strukturách. Forma těchto vzorů se jevila téměř identická při jakékoli velikosti a vyskytovala se přirozeným způsobem ve všech věcech. Mandelbrot rovněž zjistil, že tyto fraktály lze vyjádřit matematicky a že je lze vytvořit pomocí velmi malých konečných algoritmů a dat. Svá zjištění popsal v knize "Fraktální geometrie přírody" v roce 1977. V této knize uvedl tuto myšlenku: "Tradiční geometrie se svými přímými čárami a hladkými povrchy nepřipomíná geometrii stromů, mraků a hor. Zatímco fraktální geometrie se svými zavinutými pobřežími a detaily ad infinitum ano. Touto teorií získal svět počítačů nástroj k vytváření umělých a přesto reálně vypadajících tvarů.
Dalším důležitým dílem byla práce Johna Hutchinsona z roku 1981, kde popsal nové odvětví matematiky dnes známé jako "Iterated Function Theory". Na toto dílo navázal Michael Barnsley s knihou "Fractals Everywhere". V ní definoval "Iterated Functions Systems" a jaké vlastnosti musí mít, aby pomocí nich bylo možné reprezentovat obraz.
Z těchto teorií vyplynula zajímavá možnost. Jestliže je jednom směru možné fraktálovou matematikou popsat přirozeně vypadající obraz, nebylo by ji potom také možné, v opačném směru použít ke kompresi obrazu? Popis obrazu pomocí IFS je znám jako inverzní problém. Tento problém je stále nevyřešen.
Barnsley v roce 1987 založil společnost "Iterated Systems Incorporated" a nechal si patentovat vlastní postup na řešení inverzního problému. Zároveň v časopisu BYTE publikoval své výsledky a uvedl i několik příkladů obrazů zkomprimovaných pomocí IFS, u kterých dosáhl kompresního poměru 10 000:1. Později ovšem připustil, že komprese každého z nich trvala okolo 100 hodin na jednom z nejrychlejších počítačů té doby. A to dokonce s nezbytnou asistencí člověka.
V roce 1988 Barnsleyho student Arnauld Jacquin modifikoval IFS. Změna spočívala v tom, že se již v obrazu nehledaly věrné kopii obrazu celého, ale pouze jeho částí. Nový postup byl pojmenován Partitioned IFS. Změnou byla umožněna plná automatizace komprimačního algoritmu, ovšem na úkor kompresního poměru. Ten se nyní pohyboval v rozmezí 8:1 až 50:1. Přesto jsou všechny současné fraktálové kompresní algoritmy založeny na Partitioned IFS. I tento nový postup byl patentován Barnsleym.
Vlastnosti fraktální komprese
- Ztrátová
- Nehledá se věrná kopie obrazu (části obrazu), stačí přibližná. Z toho plyne, že degradace obrazu, která vzniká je jiného druhu než u běžných kompresních algoritmů (JPEG). Díky fraktálním složkám obrazu se změny jeví mnohem přirozeněji. Důsledkem toho jsou obtíže při srovnání úspěšnosti fraktální komprese oproti například JPEGu. To proto, že se dá jen těžko porovnat kvalita obrazu zkomprimovaného při stejném kompresním poměru oběma algoritmy, vzhledem k tomu že ztráta kvality se projeví odlišně.
- Asymetrická
- Komprese obrazu trvá několikanásobně déle než dekomprese.
- Fraktální interpolace
- Dekomprimovaný obraz má znaky fraktálu. Je možné ho zvětšovat prakticky donekonečna a stále se objevují nové detaily (neobsažené v původním komprimovaném obraze, tj. dopočítané).
- Konstantní poměr ztráty kvality a míry komprese
- Na rozdíl od JPEG klesá kvalita obrazu po kompresi víceméně lineárně s růstem kompresního poměru.
- Nezávislá na barevné hloubce obrazu
- Velikost dat po kompresi je stále stejná bez ohledu na počet bitů na pixel v komprimovaném obraze. Z toho plyne, že kompresní poměr se zlepšuje lineárně s počtem bitů na pixel.
- Vhodné na fotografie
- Fraktální komprese dosahuje lepších výsledku (kvality) při kompresi přirozených obrazů (fotografií) než obrazů umělých (kreseb, náčrtků, počítačové grafiky).
- Patentovaná
Klasický přístup
Princip
IFS se připodobňuje k Mnohonásobné zmenšovací kopírce (MZK). MZK má oproti běžné kopírce tyto vlastnosti:
- Má několik sad čoček, které vytvářejí několik překrývajících se kopií originálu.
- Každá sada čoček zmenšuje velikost originálu.
- Kopírování probíhá iterativně. Vstupem do dalšího cyklu je výstup předchozího.
- Vstupem může být libovolný obraz.
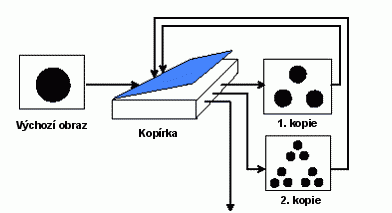
V klasickém IFS se v obraze vyhledává sebepodobnost mezi celým obrazem a jeho zmenšenými kopiemi v něm. V běžných obrazech, je ale možné nalézt tuto podobnost jen zřídka. Na fotografii krajiny mohou být stromy, tráva, kopce a obloha. Nalézt v obraze zmenšený vzor, obsahující všechny tyto součásti je v podstatě nemožné. Tento problém narůstá, pokud jsou na fotografii lidé nebo budovy.
Dalším faktorem je, že klasický přistup neobsahuje postupy, jak se vypořádat se světelnou intenzitou a barevnými vlastnostmi v různých částech obrazu.
Ke klasickému IFS lze říci, že je to zajímavý a nový přístup ke kompresi obrazu, ale v praxi bohužel nepoužitelný. Úspěchů lze dosáhnout jen s uměle vytvořenými obrazy, dva nejznámější jsou "Sierpinského trojúhelník" a "Spleenwortova kapradina".

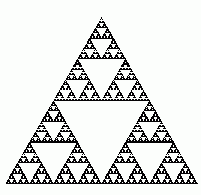

Teoretické základy
Tato kapitola je k dispozici jen ve verzi pro stažení (ve formátu Word).
Současný přístup
Doménové a řadové bloky
Jak již bylo řečeno, všechny současné fraktální kompresní algoritmy vycházejí z Partitioned IFS. Tato metoda obchází nemožnost nalezení věrné zmenšené kopie celého obrazu tím, že hledá jen kopie jeho částí. Vychází z předpokladu, že když rozdělíme obraz na celky s podobnými vzory (tedy například na oblohu, trávu, stromy), bude jednodušší nalézt podobnosti mezi těmito celky a jejich částmi. V praxi se toto provádí rozdělením obrazu na pravidelné bloky a hledání jejich větších kopií kdekoliv jinde v obrazu. Znázornění postupu viz obrázek.
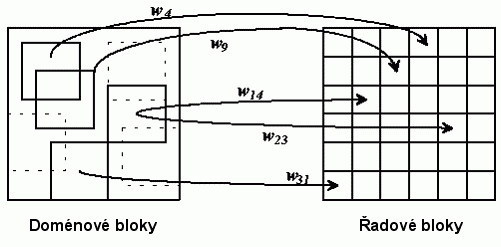
Při kompresi se obraz rozdělí na pravidelné řadové bloky (range blocks), které se nepřekrývají (pravá strana schématu). Ke každému z těchto bloků je dohledáván nejpodobnější doménový blok (levá strana schématu). Doménové bloky se mohou překrývat a nemusí dohromady pokrývat celou plochu obrazu.
Poznámka 1: Doménové i řadové bloky jsou vybírány ze stejného obrazu, oddělené znázornění na schématu je jen pro větší přehlednost.
Poznámka 2: Doménové bloky jsou zpravidla větší než řadové, to zajistí konvergenci obrazu při dekompresi. Pokud by většina doménových bloků nebyla větších než jim odpovídající řadové, probíhala by dekomprese donekonečna, resp. by byla nemožná. Z tohoto důvodu většina kompresních programů ani neumožňuje přiřazení doménového bloku k řadovému bloku, který je větší.
Tvar bloku může být v podstatě libovolný, v praxi se ale většinou využívá čtvercový tvar. Velikost doménového bloku je celočíselným násobkem velikosti řadového bloku, nejčastěji dvojnásobkem. Řadový blok mívá velikost 8×8 pixelů (příp. 4×4, 16×16, 32×32) a odpovídající doménový 16×16 (resp. 8×8, 32×32, 64×64).
Úpravy doménových bloků
Aby se zvýšila pravděpodobnost nalezení podobného doménového bloku, každý z nich se různými metodami upravuje. Nejběžnějšími úpravami je změna jasu a kontrastu pixelů bloku, dále osm symetrických transformací. Tyto transformace jsou následující:
- Otočení o 0 stupňů (resp. žádná transformace)
- Otočení o 90 stupňů
- Otočení o 180 stupňů
- Otočení o 270 stupňů
- Otočení podle horizontální osy
- Otočení podle vertikální osy
- Otočení podle první diagonály
- Otočení podle druhé diagonály
Víceúrovňové párování
Jednoduchý postup párování řadových bloků s doménovými má tu nevýhodu že nebere v úvahu obsah bloku. To neumožňuje zefektivňovat přiřazení podle úrovně detailů v bloku obsažených. Pokud blok neobsahuje žádné detailní struktury (například obloha, tráva...), je běžně možné nalézt podobný pár i při velikosti řadového bloku 32×32 pixelů. Naopak v blocích s velmi detailními strukturami by bylo vzhledem k zachování kvality obrazu hledat páry k řadovým blokům o velikosti 4×4 pixely.
Nejčastějším řešením tohoto problému je hierarchické párování. Při jeho použití se jako základní velikost řadového bloku použije např. 16×16 pixelů. K bloku této velikosti se dohledá nejpodobnější pár. Pokud se přesnost shody vejde do daného intervalu je vyhledaný pár přijat. Pokud ne, rozdělí se blok na čtyři stejně velké bloky (8×8 pixelů) a ke každému zvlášť je hledán doménový blok. Tímto způsobem je možné postupovat iterativně na stále menší bloky. Nejčastější počet používaných úrovní jsou dvě (bloky o velikosti 8×8 a 4×4) a tři (16×16, 8×8 a 4×4).
Existují dvě varianty hierarchického párování, úplné a částečné. Při použití první se blok vždy dělí na čtyři části a ke každé z nich se dohledává nový pár. Při použití druhé složitější varianty, se dopočítá přesnost shody pro každou ze čtyřech částí bloku a pár se dohledává jen k těm, kde není splněna daná shoda. Je zároveň nutné si zapamatovat i párový doménový blok pro celý rozdělený řadový blok, což u jednodušší varianty není nutné, protože čtyři podbloky pokryjí celou jeho plochu.


Alternativní přístupy k řešení dělení bloku je dělení jen na poloviční obdélníkové části nebo dělení podle diagonál na trojúhelníky. Tyto alternativy ale nepřinesly zlepšení kvality komprimovaného obrazu.
Urychlení kompresního algoritmu
Vyhledávání nejpodobnějšího doménového bloku ke každému řadovému postupným vzájemným porovnáváním je nejnáročnější částí algoritmu. Z tohoto důvodu vzniklo mnoho variant kompresního algoritmu, které se liší způsobem, jakým omezují počet prováděných porovnání a tím i urychlují kompresi.
Těžká hrubá síla
Tato metoda nijak neomezuje počet porovnání. Příklad: Máme obraz o velikosti 256×256 pixelů, řadový blok o velikosti 8×8 a doménový 16×16 pixelů. To nám dává (256/8)2=1024 řadových bloků, kterým je třeba dohledat nejpodobnější doménový blok. Při libovolném umístnění je doménových bloků (256-16+1)2=58 081. Pokud použijeme osm symetrických operací, je celkový počet porovnání, který je potřeba k nalezení všech přiřazení řadový-doménový blok, roven 1024×58 081×8=475 799 552 (475 miliónů).
Metoda "těžké hrubé síly" sice nalezne nejlepší přiřazení, ale pro svou časovou náročnost se nepoužívá. Uvádím ji zde jen pro srovnání jako horní hranici doby trvání. Každá z dále uvedených metod na jednu stranu urychluje kompresi, na druhou stranu snižuje kvalitu zkomprimovaného obrazu.
Lehká hrubá síla
Nejjednodušší způsob, jak omezit množství porovnání, je omezení možných poloh doménových bloků. Při porovnání se například uvažují jen bloky na sudých souřadnicích, což omezí počet srovnání na čtvrtinu oproti metodě "těžké hrubé síly". Omezení může samozřejmě být i rozsáhlejší.
Mimo urychlení doby komprese může tato metoda zvýšit i kompresní poměr, protože k uložení polohy doménového bloku ve výstupním souboru je třeba méně bitů. Při použití této úspory musí ovšem dekomprimační program vědět, jakým koeficientem uloženou polohu vynásobit.
Omezení prohledávané oblasti
Při hledání podobného doménového bloku se neprohledává celý obraz, ale jen určitá omezená plocha. Například jen okolí řadového bloku do určité vzdálenosti. Více sofistikované alternativy rozdělí obraz nejdříve na oblasti s podobnými vzory a následně prohledávají jen oblast, ve které leží daný řadový blok.
Spirála
Vyhledávání do spirály je určitou modifikací předchozí metody. Prohledávání se začne na souřadnicích, kde leží řadový blok. Dále se pokračuje ve spirále. V tomto případě se nehledá nejlepší pár, ale hledaní skončí v okamžiku, kdy je nalezen doménový blok s dostačující podobností.
Vyhledávání "na místě"
Tato metoda je stejně jako metoda "těžká hrubá síla" uváděna jen pro srovnání jako dolní mez dosažitelné doby vyhledávání párů. Jako párový doménový blok je vždy vybrán ten, který je na stejných souřadnicích jako řadový blok.
Kategorizace doménových bloků
Do této kategorie spadá mnoho různých metod. Pro všechny obecně platí, že se před započetím hledání párů rozdělí všechny doménové bloky do několika kategorií, případně ohodnotí podle určitého kritéria na spojité škále. Každý řadový blok se při prohledávání zařadí resp. ohodnotí stejným způsobem a dále se již porovnává pouze se stejně zařazenými doménovými bloky.
Jednou z nejjednodušších kategorizačních metod je rozdělení doménových bloků do jedné ze tří kategorií rozlišených podle struktury v bloku obsažené. V jedné skupině budou bloky se zřetelnou hranou, v další bloky s určitou strukturou (ale ne hranou) a v poslední bloky bez zřetelné struktury. U každého doménového bloku se také určí jeho zařazení do jedné z těchto kategorií a podobný doménový blok se již vyhledává pouze v rámci ní.
Další složitější používaná kategorizační metoda ohodnocuje každý blok na základě dvou kritérií: střední hodnoty úrovně šedi pixelů bloku a počtu dominantních barev v bloku. Tím se vytvoří dvourozměrná matice. Každý řadový blok se ohodnotí podle stejných kritérií. Dále se již prohledávají jen doménové bloky s hodnotami charakteristik v daném intervalu okolo hodnot řadového bloku. Tento algoritmus je obtížně implementovatelný, vzhledem k těžkostem při specifikaci charakteristik (definice "dominantní barvy" ...).
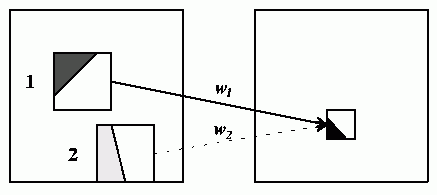
Jiná kategorizační metoda rozděluje doménové bloky do 72 kategorií a to na základě dvou charakteristik. Nejdříve je každý blok zařazen do jedné ze tří základních kategorií (viz obrázek). Zařazení se provádí tak, že se blok rozdělí na čtyři kvadranty a pro každý se spočítá střední hodnota hodnot pixelů. Každá kategorie má dané pořadí kvadrantů podle středních hodnot. Pokud nelze zařadit blok do žádné z nich hned, je to možné po aplikaci jedné z osmi symetrických transformací. Výsledkem je tzv. kanonická pozice. V rámci každé třídy se podle pořadí hodnot rozptylu rozdělí do dalších 4!=24 kategorií. Celkový počet tříd je tedy 3×24=72. Při hledání párů se prohledává již jen ta kategorie, do které by patřil daný řadový blok. Navíc již není nutné provádět symetrické operace, protože srovnávaný doménový i řadový blok jsou již v kanonické pozici.

Jako poslední bude popsána metoda, která do skupiny kategorizační spadá jen částečně. Tato metoda je specializována na použití s hierarchickým párováním. Nejdříve je pro každý blok na jednotlivých úrovních spočítán rozptyl a podle jeho hodnoty jsou bloky seřazeny. Potom jsou ze vzniklé škály vybrány jen bloky spadající do určitého intervalu, například podle následujícího klíče:
- úroveň 64×64: všechny ze spodních 10% škály (hladké oblasti)
- úroveň 32×32: polovina z horních 10% (hrany), polovina z intervalu 20-50%
- úroveň 16×16: polovina z horních 10%, polovina z intervalu 50-80%
- úroveň 8×8: všechny z horních 10%
Tento heuristický postup je založen na faktu, že velké bloky (64×64) většinou pokrývají oblasti bez znatelné struktury (obloha...) a malé bloky spíše místa s ostrými hranami.
Obecně
Některé uvedené metody lze vzájemně kombinovat. Například principem postupu "lehká hrubá síla" lze rozšířit každou z dalších uvedených metod. Další možností vylepšení je vyřazování duplicitních resp. velmi podobných doménových bloků z porovnávání.
Dekomprese
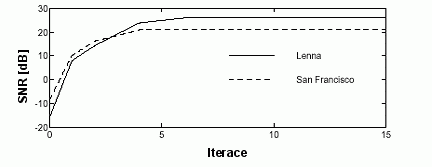
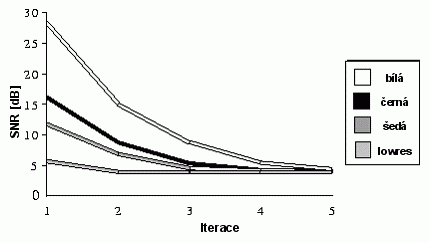
V porovnání s kompresí je dekomprese velmi rychlá a jednoduchá. Jako základ se použije libovolný obraz a na něj se iterativně aplikují uložená transformační pravidla. Vstupem do každého dalšího cyklu iterace je výstup předchozího. Již po dvou iteracích se objevují zřetelné detaily obrazu. Při osmibitové barevné hloubce je dekomprimace dokončena po přibližně 4 iteracích.
Jako výchozí obraz se obvykle používá jednobarevná šedivá plocha. S ní se dosahuje nejrychlejších výsledků, tj. obraz se stabilizuje po nejmenším počtu iterací. Ještě lepších výsledků lze dosáhnout pokud se jako výchozí použije méně kvalitní kopie cílového obrazu, ta ale většinou není dostupná. Transformační pravidla lze aplikovat na libovolný obraz, může jím být i zcela jiná fotografie. Tuto variantu jen uvádím jako zajímavost, v praxi nemá uplatnění, jen zvyšuje počet iterací potřebných k rekonstrukci obrazu.


Kompresní poměr
Výpočet kompresního poměru, kterého lze dosáhnout popsanými metodami, uvedu na příkladu. Předpokládáme obraz s velikostí 256×256 pixelů s barevnou hloubkou 8 bitů. Velikost řadového bloku je 8×8 pixelů, doménový blok je 2× větší. Máme tedy 1024 řadových bloků, tj. 1024 transformací, které je nutné uložit do výstupního souboru. Do kolika bitů se vejde informace o jedné transformaci?
| Horizontální souřadnice | 8 (6) bitů |
| Vertikální souřadnice | 8 (6) |
| Použitá symetrická operace | 3 |
| Faktor úpravy kontrastu | 5 (8) |
| Faktor úpravy jasu | 6 (8) |
| Celkem | 30 bitů |
|---|
Při 30 bitech na jednu transformaci je celková velikost výstupních dat 30×1024=30 730 bitů. Velikost dat vstupního obrázku je 256×256×8=524 288 bitů. Kompresní poměr je tedy 524 288/30 730=17,06. Tato hodnota se může měnit vzhledem k velikosti řadového/doménového bloku a to jak nahoru tak dolů. Dále ji převážně pozitivně ovlivňuje použití hierarchického párování. Kompresní poměr zlepšuje použití principu "lehké hrubé síly". S růstem velikosti obrazu roste i počet bitů nutných k uložení pozice doménového bloku, tedy klesá kompresní poměr. Jak již bylo uvedeno, velikost výstupních dat není ovlivněna barevnou hloubkou vstupního obrazu. Z toho plyne, že s růstem barevné hloubky se zlepšuje i kompresní poměr. Pokud by náš modelový obrázek měl barevnou hloubku 24 bitů (True color), byla by velikost vstupních dat 256×256×24=1 572 864 bitů, velikost výstupních dat se nezmění, kompresní poměr tedy bude 1 572 864/30 730=51,18.
Srovnání s JPEG
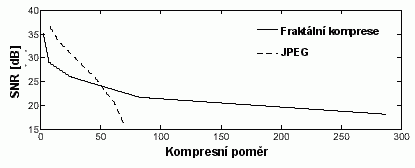
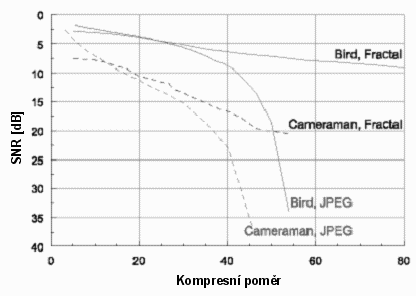
Srovnání s kompresí JPEG je obtížné, vzhledem k odlišnosti chyb vnesených do komprimovaného obrazu těmito algoritmy. Obecně ale ne vždy platí, že zkreslení obrazu fraktální kompresí je přirozenější než zkreslení kompresí JPEG.
Obecně lze říci, že pro nízké kompresní poměry dosahuje JPEG lepší kvality než fraktální komprese, pro větší kompresní poměry je tomu naopak. Za zlomový bod se považuje kompresní poměr 1:10-1:40 (liší se podle obsahu obrazu). To podporuje i fakt, že po tomto bodě obsahují obrazy komprimované JPEG tolik šumu, že jsou v podstatě nepoužitelné. Na rozdíl od JPEG dochází u fraktální komprese ke zkreslování pozvolna s růstem kompresního poměru.
Použití
Fraktální komprese se hodí zejména na kompresi přírodních obrazů. Velmi špatných výsledků je dosahováno při práci s obrazy, které obsahují text a kresby. Tyto části obrazu jsou po kompresi deformovány, někdy dokonce úplně zmizí, to je typické hlavně pro přímé čáry, které směřují diagonálně k hranám řadových bloků.
| Typ obrazu | Nízká komprese | Vysoká komprese |
|---|---|---|
| text, kresby | nízká | nízká |
| počítačová grafika | nízká až dobrá | nízká až průměrná |
| fotografie | dobrá | velmi dobrá |
Jednou ze zajímavých vlastností je "fraktální interpolace". Používaný počet iterací při dekompresi je dán jen rozlišovací schopností obrazovky (nebo jiného zařízení). Je ale možné provádět další cykly. Od určitého okamžiku se v dekomprimovaném obraze objeví detaily, které v původním obraze nebyly obsaženy. Tomuto jevu se říká fraktální interpolace. Na rozdíl od klasické interpolace používané k zvětšování bitmapových obrazů, se u fraktální interpolace neobjevují umělé čtverhranné útvary.
Použitá literatura
- [1]
- John Kominek: Advances in Fractal Compression for Multimedia Applications; http://link.springer-ny.com/link/service/journals/00530/papers/7005004/70050255.pdf
- [2]
- Edward R. Vrscay: A Hitchhiker's Guide to "Fractal-Based" function Approximation and Image Compression; ftp://links.uwaterloo.ca/pub/Fractals/Papers/Waterloo
- [3]
- John Kominek: Introduction to Fractal compression; http://www.faqs.org/faqs/compression-faq/part2/section-8.html
- [4]
- Carsten Frigaard, Jess Gade, Thomas T. Hemmingsten a Torben Sand: Image Compression Based on a Fractal Theory; ftp://links.uwaterloo.ca/pub/Fractals/Papers/Waterloo
- [5]
- James D. Murray, William van Ryper: Encyklopedie grafických formátů, Computer press, 1997